This article describes the most important AMBA bus architectures and how they evolved to accommodate to the ever increasing complexity of SoC technology. Digital designers will learn about the differences between common bus-based and recent transaction based interconnection architectures.
AHB revisited
AHB (Advanced High-performance Bus) first appeared to the public as part of AMBA 2.0 Specification and set out to replace ASB (Advanced System Bus) as the basis for ARM based System on Chip (SoC) interconnect fabrics between processor(s), internal/external memory controllers, and other high-bandwidth peripherals.
Both being traditional bus systems, AHB and ASB are fairly similar in concept. The newer AHB, with only unidirectional (multiplexed, rather than tri-stated) signals, has been specifically aimed at synthesizable, DFT-friendly ASIC designs.
AHB supports single data access and various types of burst accesses (including wrapping bursts to support cache line fill operations). Each transfer is defined by an address and a data phase where the address phase of one transfer occurs during the data phase of the previous transfer.
Underlying AHB is a traditional bus architecture with arbitration between multiple masters. The protocol supports advanced features such as SPLIT and RETRY signaling in cases where a slave is not able to respond immediately. The master that had been granted the bus will back off and other masters will get a turn.
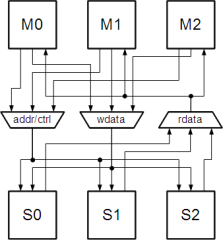
Multi-layer AHB and AHB-Lite
Although traditional multiplexed multi-master systems are still quite common, little over a decade ago the ARM SoC world started shifting towards crossbar switched interconnects, in the form of multi-layer busses. This was a rather important initial step which led over time to some critical improvements:
Each layer of the bus is an independent single master AHB system. Instead of a rather complex monolithic multiplexing scheme, a multi-layer AHB bus architecture with M masters and S slaves is structured as M X 1:S multiplexers plus S X M:1 slave multiplexers all connected to separate arbitration and decoding logic.
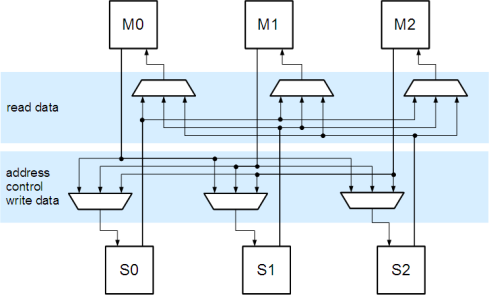
Consequently, multiple masters can talk to multiple slaves concurrently, as long as no two masters try to access the same slave at the same time. Think of a DMA controller moving data from a receiver into a memory region, while the processor continues to execute code in a different memory region.
All arbitration and protocol complexity moves into the fabric. The interface implementation becomes simpler as a number of unneeded signals, most notably HGRANT and HBUSREQ, can be removed along with their associated protocol. Although not a necessary consequence of the multi-layer architecture, getting rid of the unpopular SPLIT and RETRY handshaking mechanism was another advantage.
With the advent of AMBA3 this AHB subset has been standardized upon as AHB-Lite.
AXI3
With modern Systems on Chip including multi-core clusters, additional DSP, graphics controllers ond other sophisticated peripherals, the system fabric poses a critical performance bottleneck. The AHB protocol, even in its multi-layer configuration cannot keep up with the demands of today's SoC. The reasons for this include:
- AHB is transfer-oriented. With each transfer, an address will be submitted and a single data item will be written to or read from the selected slave. All transfers will be initiated by the master. If the slave cannot respond immediately to a transfer request the master will be stalled. Each master can have only one outstanding transaction.
- Sequential accesses (bursts) consist of consecutive transfers which indicate their relationship by asserting HTRANS/HBURST accordingly.
- Although AHB systems are multiplexed and thus have independent read and write data busses, they cannot operate in full-duplex mode.
An AXI interface consists of up to five channels (write address, write data, write response, read address, read data/response) which can operate largely independently of each other. Each channel uses the same trivial handshaking between source and destination (master or slave, depending on channel direction), which simplifies the interface design.
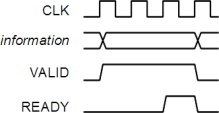
Unlike AHB(-Lite), in the new AXI (Advanced eXtensible Interface) the P-t-P (point-to-point) concept is not an afterthought but is the central focus of the protocol design.
In AXI3 all transactions are bursts of lengths between 1 and 16. The addition of byte enable signals for the data bus supports unaligned memory accesses and store merging.
The communication between master and slave is transaction-oriented, where each transaction consists of address, data, and response transfers on their corresponding channels. Apart from rather liberal ordering rules there is no strict protocol-enforced timing relation between individual phases of a transaction. Instead every transfer identifies itself as part of a specific transaction by its transaction ID tag. Transactions may complete out-of-order and transfers belonging to different transactions may be interleaved. Thanks to the ID that every transfer carries, out-of-order transactions can be sorted out at the destination.
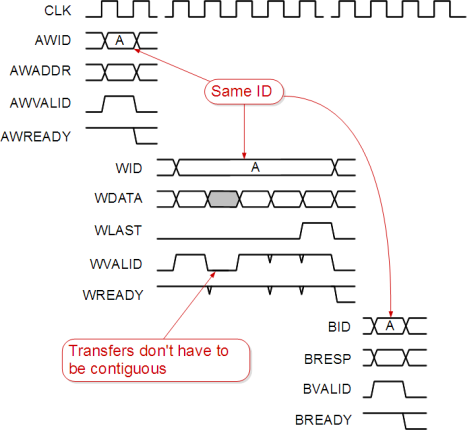
This flexibility requires all components in an AXI system to agree on certain parameters, such as write acceptance capability, read data reordering depth and many others.
Due to the vast number of signals that make up a read/write AXI connection, routing a large AXI fabric could be thought of as rather challenging. However, the independent channels in an AXI fabric make it possible to choose a different routing structure depending on the expected data volume on that channel. Given a situation where the majority of transactions will transfer more than one data item, data channels should be routed via crossbar so that different streams can be processed at the same time. Address and response channels experience rather lower traffic and could perhaps be multiplexed.
Some experts consider it an advantage to provide AXI only at the interface level, while a special packetized routing protocol is used inside the fabric, a so called Network-on-Chip (NoC).
AXI4
AXI4 is the latest revision of the AXI protocol described above. Functionality has been added and several known issues in AXI3 have been addressed to ensure that AMBA busses remain the dominant standard in SoC connectivity. Some key points:
The maximum burst length has been increased from 16 to 256 transfers for certain types of bursts (INCR, non-exclusive).
Additional Quality-of-Service signaling has been added, where the finer details of the interpretation are implementation defined.
AXI4 defines address regions for slaves, which allows implementations of memory perspectives on the bus level. No doubt this will be used at some point in the future to break the 4GB address boundary. [Update: Since this article has been written, Cortex-A15 was announced with this very functionality]
Some ordering requirements and transfer dependencies have been refined, as have the meanings of the cache policy signals AxCACHE. Abstract memory types as defined by ARMv6/v7 architectures and multicore architectures are much better represented by these changes.
Implementation-defined per-channel sideband signals are now officially supported as AxUSER.
Legacy (AHB) locked transfers are no longer supported. The entire concept that a master can request exclusive access to the entire bus doesn't fit within the idea of a switched interconnect. The one-and-only ARM instruction causing this signal to be asserted is no longer supported in the v7 architectures.
A rather significant change seems to be the banning of write interleaving, which could help improve the system throughput. In practice, removing write interleaving from this part of the AMBA standard makes certain aspects of the AXI protocol easier to handle. Write interleaving is hardly used by regular masters but can be used by fabrics that gather streams from different sources. With the new AXI4-Stream protocol (see below), write interleaving is still available for fabrics.
AXI4-Stream
The new AXI4-Stream protocol was designed for streaming data to destinations that are not memory mapped internally. Display controllers, transmitters, but also routing fabrics are among the target applications for this new protocol.
Building upon the proven simple AXI channel handshake AXI4-Stream is essentially an AXI write data channel with additional control signals and a slightly modified protocol. The burst (packet) length is not restricted and the number of bytes of the data signal TDATA can be an arbitrary integer including zero.
AXI4-Lite
As described so far the focus of AXI has been on high-performance data transfer, but what about the low-end - hardware registers, configuration, etc? With good old APB there is an established, robust interface, which received an upgrade in AMBA3 extending it with slave response signaling (PERROR, PREADY), a feature that was missed dearly by designers.
You may ask what exactly was the issue with APB anyway? The answer is the bridge. In a traditional system, including AMBA3, one or more of the slaves are bridges between the main system protocol (AHB, AXI) and APB. The intention was that with many small peripherals on a "real" bus including the multi-layer variant, the fan-out of multidrop signals (HWDATA, HADDR in AHB) would be too high. A typical bridge supports up to sixteen slaves, which are assigned fragments of the address region occupied by the bridge itself so that all APB peripherals connected to this bridge are in one contiguous address region.
In modern interconnects, you may find built-in 1:1 bridges which connect between system bus and a single APB slave, enabling higher flexibility. Still a bridge though.
AXI4-Lite addresses this last issue by defining certain restrictions that would allow a slave to be connected directly to an AXI fabric. In AXI4-Lite, you might say that AXI gets "dumbed" down to a few basic transaction types. The burst length is fixed to one data transfer, transfers are non-cacheable and non-bufferable, exclusive access is not allowed and access width must always be the same as data bus width. This is supposed to make the interface design simple enough to be implemented quickly in custom IP.
Summary
Over the years AMBA has continued to provide state-of-the-art solutions for SoC interconnects. With the relatively recent addition of the AXI4 protocol family ARM maintains a competitive advantage in the field of high-performance SoC, while at the same time AHB-Lite is still available for less demanding architectures.
References

